Writing a JSON Parser in C
January 20, 2024
This post is long overdue.
Grab a coffee, this is an in-depth article and will take a while.
Newly equipped with the knowledge of writing a parser and a compiler for the makeshift programming language called lox, I was determined to do something on my own, without relying on any tutorials. I decided to start with the simplest of all, a JSON Parser. I completed writing a JSON Library called blason in the beginning of December 2023, this blog is a walkthrough of the incredible journey.
JSON (JavaScript Object Notation)
JSON is omnipresent - me (2023)
Contents: - Writing a JSON Parser in C - Grammar - Parser - Lexer - Syntax Parsing - void ptrs conversion to struct - Object Manipulation
Grammar
JSON is a data interchange format and its structure can be described using a context-free grammar. Presence of context-free grammar implies a recursive descent parser can be written, and that is what I did.
The McKeeman form of JSON grammar is loosely described in a side note on the JSON org site, however the details can be found in the redirect. If you’re familiar with the Backus-Naur Form(BNF) grammar, then McKeeman form is only a simplified version of it.
Douglas Crockford, the creator of JSON had business cards with the whole grammar printed on the back of them! Image
{kind=link}
A simplified flow of the structure, visually:
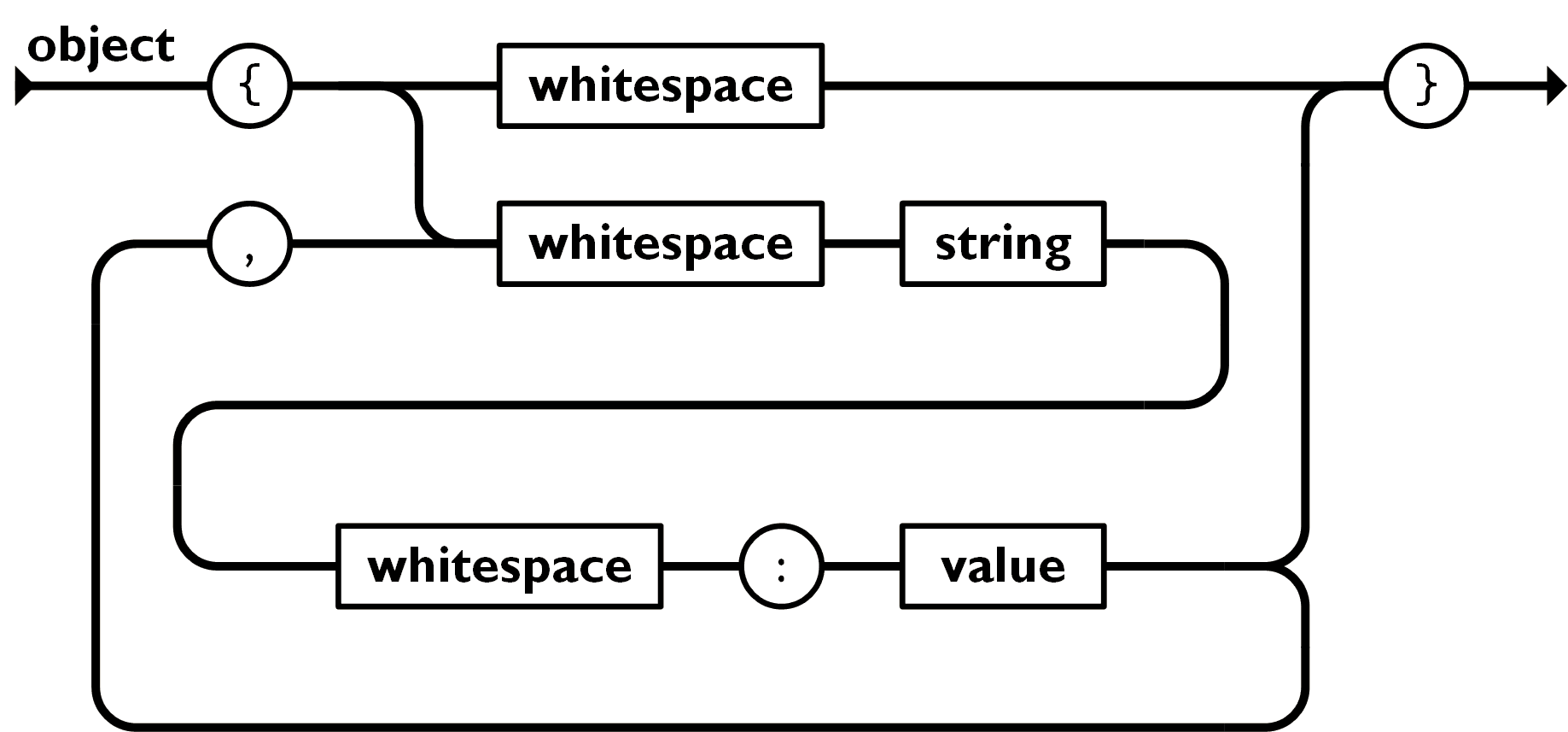
More visuals can be found here.
Broadly speaking, the entire notation can be described as follows:
- An object contains members
- A member contains pair(s)
- A pair contains a key(always a string) and a value
- A value can contain a terminal symbol, an array or another object.
- An array contains element(s)
- An element contains value(s)
Parser
Okay, now that we have the entire flow in our mind, it’s time to start writing the parser.
The whole process is divided into the following two steps: 1. Lexer 2. Syntax Parsing
We’ll start with the Lexer.
Lexer
This stage is also referred to as Tokenizing.
Our implementation of the lexing phase involves reading the entire file into memory and then performing the tokenization.It’s simpler to begin with, although it can be improved to read from a stream and perform tokenization on the fly.
Goal: Read each character from the json file and convert the character(s) into tokens, if valid and recognized by the specification.
Before we start reading the file, let us define the Token struct and the TokenType enum.
typedef enum {
LBRACE,
RBRACE,
LSQUARE,
RSQUARE,
NUMBER,
STRING,
COLON,
COMMA,
TRUE,
FALSE,
NIL,
TOKEN_EOF,
} TokenType;
typedef struct {
TokenType type;
int length;
char *value;
} Token;
All streams of characters that are valid and recognized by the specification will be converted into a Token struct and be given the respective TokenType enum. This is the heart of our parser. These two composite types will be used by the Lexer and the syntax analyzer.
Also, while we are here, let us define two more structs called Lexer that holds references to the start and current positions of our character stream, and Parser that holds references to current and previous tokens.
typedef struct {
char *start;
char *current;
} Lexer;
typedef struct {
Token *previous;
Token *current;
} Parser;
Now, to read the file.
- Load the file into a file descriptor
- Seek to the end, allocate a buffer with capacity of file size
- Read characters into the buffer
- Close the file, return the buffer
static char *readFile(const char *path) {
FILE *file;
file = fopen(path, "rb");
if (file == NULL) {
fprintf(stderr, "Could not open file \"%s\".\n", path);
exit(74);
}
fseek(file, 0l, SEEK_END);
size_t fileSize = ftell(file);
rewind(file);
char *buffer = (char *)malloc(fileSize + 1);
if (buffer == NULL) {
fprintf(stderr, "Could not allocate enough memory to read \"%s\".\n", path);
exit(74);
}
size_t bytesRead = fread(buffer, sizeof(char), fileSize, file);
if (bytesRead < fileSize) {
fprintf(stderr, "Could not read file \"%s\".\n", path);
exit(74);
}
buffer[bytesRead] = '\0'; // null byte
fclose(file);
return buffer;
}
We point the lexer to the beginning of the buffer.
static void lex(char *path) {
lexer.start = readFile(path);
lexer.current = lexer.start;
}
Since we need to be tokenizing one token at a time, we will need to advance one token at a time. There is a handy method to do that.
static void advance() {
parser.previous = parser.current;
parser.current = scanToken();
}
static Token *scanToken() {
skipWs();
lexer.start = lexer.current;
if (end())
return createToken(TOKEN_EOF);
char c = *lexer.current++;
if (isAlpha(c))
return literal();
if (isDigit(c) || c == '-')
return number();
switch (c) {
case '{':
return createToken(LBRACE);
case '}':
return createToken(RBRACE);
case '[':
return createToken(LSQUARE);
case ']':
return createToken(RSQUARE);
case ':':
return createToken(COLON);
case ',':
return createToken(COMMA);
case '"':
return string();
default:
fprintf(stderr, "Unknown character '%c'.\n", c);
exit(74);
}
}
fprintf() is used to write characters to an output stream such as stdout or stderr, while printf() is used to write to stdout.
skipWs() discards all the whitespaces in our character stream, since our parse will be expected to work on a minified JSON string as well.
end() checks if current char is the null byte, which marks the end of our character stream. TOKEN_EOF is used to mark the end of our token stream.
isAlpha() and isDigit() check if current char is an alphabet or a digit, respectively.
createToken(tokenType) is a generic function that creates a token struct with the given tokenType.
static Token *createToken(TokenType type) {
Token *token = (Token *)malloc(sizeof(Token));
token->type = type,
token->length = (int)(lexer.current - lexer.start),
token->value = lexer.start;
lexer.start = lexer.current;
return token;
}
We need to use malloc here, we can’t use just a designated initializer and return the object, because the created object’s life ends when the function returns, and the object will be removed from the stack memory. malloc returns a pointer to the heap memory which is long lived.
Syntax Parsing
Alright, now that we have our token stream, we can start analyzing it and putting the tokens into their respective structures.
Idea: Ensure each token is present where it should be, as per the JSON Spec. Place tokens in the ObjectJson structure, hierarchically.
Before that, let us define the required structures.
typedef enum {
OBJ_STRING,
OBJ_ARRAY,
OBJ_JSON
} ObjectType;
typedef struct {
ObjectType type;
int length;
char *value;
} ObjectString;
typedef struct {
ObjectType type;
int length;
Value *start;
} ObjectArray;
typedef struct {
ObjectType type;
struct bst *htable;
Member *members;
} ObjectJson;
typedef struct {
ObjectType type;
} Object;
ObjectJSON will contain the entire JSON object present in the file, and this will be returned after parsing is complete. ObjectArray will contain the array strucutre, and ObjectString is a generic type to contain a string present in the JSON Object. ObjectType enum contains the above three types.
Before you begin to question why each struct has ObjectType type; at the beginning of their struct definition, let us understand how a pointer is converted into a struct in the C programming language.
void ptrs conversion to struct
When you request memory using malloc, you do not get a pointer that is of the required type, you get a void * (a void pointer) instead. This void pointer is cast into a pointer to the required type. Why?
It is true that you cannot cast a memory pointer into a struct pointer without defining the struct first (forward declarations are exceptions, but definition must occur within the translation unit, in the same way static restricts visibility and invocation scope to the current translation unit).
It is also true that each struct has a definite member list, with types declared beforehand. This allows the C compiler to know which member occupies how much amount of memory, and at what position this member’s memory begins.
If you visualize memory to be a straight block of emptiness, then x amount from the beginning is occupied by the first member of the struct. This is how memory is laid out, and how typecasting also works.
Ex: consider the following struct ```c struct example { int a; long b; };
struct example ptr = (struct example)malloc(sizeof(struct example));
``
Assuming a 64-bit arch,intis of 4bytes andlongis of 8bytes.
sizeof(struct example)` returns 12bytes.
Now ptr points to 12 bytes of emptiness, that is cast into a pointer to struct example. When you try to access the second member b with ptr->b the compiler will read 8bytes with an offset of 4bytes from the beginning, and cast those 8bytes into a long type.
This is how it works. Pretty interesting stuff isn’t it?!
Now, the significance of our slight detour lies in the members of our ObjectJSON, ObjectArray and ObjectString. At compile type, we do not know what the token stream might represent, and so we need to classify the token stream into different structs at runtime, and have a mechanism to distinguish between different structs when all we have is a void pointer.
All the three structs have their first member as ObjectType enum. In the C language, an enum is by default, an int, again 4bytes. This implies:
OBJ_STRING = 1
OBJ_ARRAY = 2
OBJ_JSON = 3
Hence, when we have a void pointer ptr that we expect to be an object, we need to cast it into a pointer to struct Object, whose only member is an ObjectType type enum. Comparing the value of type with the values of OBJ_*, we find out what the block of memory represents. Depending on the value of the type member, we cast the block of memory, pointed to, by ptr, into a pointer to the respective struct. To solidify your understanding, read the following example.
void *ptr = some_method_invocation();
// expecting ptr to point to struct Object and not NULL
Object *object_ptr = (Object *) ptr;
switch(object_ptr->type){
case OBJ_STRING:
ObjectString *str = (ObjectString *) object_ptr;
break;
case OBJ_ARRAY:
ObjectArray *array = (ObjectArray *) object_ptr;
break;
default:
// throw an error or take appropriate action
}
This dual type casting process results in achieving type check at runtime, and this is exactly what we need. Powerful stuff indeed!
Let’s move on to the fun (parsing) part.
ObjectJson *parseJSON(char *path) {
lex(path);
// to set the first token in parser.current
advance();
ObjectJson *json = object();
create_bst(json);
return json;
}
parseJSON() will be called with the filepath, and our entry point into the parsing phase is the object() method.
check(type) and expect(type) are two methods that help us in determining our next steps. If you recall, JSON grammar falls under context-free-grammar and can contains recursive relations to its own rules, hence next steps can only be determined using lookahead. The two util functions help us with a lookahead of 1 token at a time, and that is all we need.
check(type) tells us if the next tokens tokenType matches with type.
expect(type) throws an error if the next token isn’t what is specified by the grammar, and advances if it is.
static ObjectJson *object() {
if (!check(LBRACE))
return NULL;
ObjectJson *json = (ObjectJson *)malloc(sizeof(ObjectJson));
json->type = OBJ_JSON;
json->htable = NULL;
expect(LBRACE, "Expect '{' at the beginning.");
if (check(RBRACE))
json->members = NULL;
else
json->members = members();
expect(RBRACE, "Expect '}' after members.");
// create_bst(json);
return json;
}
Ignore the htable and create_bst(json) references for now, we will circle back to them after the parsing phase is complete.
- An Object contains members. Members are spearated with COMMA\s.
static Member *members() {
Member *member = (Member *)malloc(sizeof(Member));
member->next = NULL;
pair(member);
while (match(COMMA)) {
member->next = members();
}
return member;
}
match(type)is another helper function, similar toexpect(type), except it doesn’t throw an error and exit when the next tokens type isn’ttype.
In struct ObjectJSON we have Member *members;. This implies, we are using a singly linked list to store the members of our current JSON object, after parsing. Each member’s next pointer points to neighbouring member, if there is one, else is NULL.
- A member contains pairs.
- A pair contains a key(always a string) and a value
static void pair(Member *member) {
expect(STRING, "Expect string as key in a pair.");
member->key = *parser.previous;
expect(COLON, "Expect ':' between key and value in a pair.");
member->value = value();
}
Technically, each key is a token with tokenType as STRING, and hence member->key naturally points to a token, present at the location pointed to, by parser.previous. (Too many redirections..beautifully annoying!)
To keep this already long post from growing indefinitely, lets stick to understanding the parsing logic behing OBJ_STRING and OBJ_ARRAY (you are welcome to read the entire source code for all types, including terminal symbols, in my gitub repo).
- A value can contain a terminal symbol, an array or another object.
Now, let us define struct Value
typedef enum {
VAL_BOOL,
VAL_NIL,
VAL_NUMBER,
VAL_OBJ,
} ValueType;
// tagged union
struct Value {
ValueType type;
union {
bool boolean;
double number;
Object *obj;
} as;
struct Value *next;
};
A Tagged Union is a struct that encapsulates a C union along with a member, often used to identify the contents of the C union embedded within. To refresh your memory, a C struct can contain any number of members of various types, however a C union whose definition contains N members, can contain only 1 member inside itself, but the memory occupied by the union is equal to the largest memory occupied by any of its N members. Don’t worry if this feels confusing, it is simple once you get the idea. Its a beautiful concept.
In the current context, our tagged union struct Value contains a ValueType type member, used to identify the contents of the as union. The as union can contain either of boolean, number, *obj members, but the memory footprint of this as union is equal to sizeof(double) which is 8bytes(assuming a pointer also occupies 8bytes of memory). A tagged union is one of the many optimizations often used in the world of implementing dynamic type checking in C, I will write a detailed post on a couple of techniques, soon.
Values are also stored as a linked list in the array object.
static Value *value() {
switch (parser.current->type) {
case STRING: {
ObjectString *string = (ObjectString *)malloc(sizeof(ObjectString));
string->type = OBJ_STRING;
string->length = parser.current->length;
string->value = parser.current->value;
Value *value = (Value *)malloc(sizeof(Value));
value->type = VAL_OBJ;
value->as.obj = (Object *)string;
advance();
return value;
break;
}
case LSQUARE: {
ObjectArray *arrayObj = array();
Value *value = (Value *)malloc(sizeof(Value));
value->type = VAL_OBJ;
value->as.obj = (Object *)arrayObj;
return value;
break;
}
}
- An array contains element(s)
- An element contains value(s)
Handling when the current token is a string is pretty straightforward, create an ObjectString and you’re done. Recursive evaluation comes into picture when creating an array since any element can be present inside.
static ObjectArray *array() {
expect(LSQUARE, "Expect '[' at the beginning of an array.");
ObjectArray *arrayObj = (ObjectArray *)malloc(sizeof(ObjectArray));
arrayObj->type = OBJ_ARRAY;
if (check(RSQUARE))
arrayObj->start = NULL;
else
arrayObj->start = elements();
expect(RSQUARE, "Expect '[' at the beginning of an array.");
return arrayObj;
}
An array contains elements, and elements themselves are values separated by COMMA\s.
static Value *elements() {
Value *start = value();
Value *end = start;
while (match(COMMA)) {
end->next = value();
end = end->next;
}
if (end != NULL)
end->next = NULL;
return start;
}
The flow of parsing an array can be summarized as follows:
ObjectJSON → Member → Pair → Value → ObjectArray → elements() → Value(repeat from Value when terminated with a COMMA)
Interesting!
If the file is as expected, then this ends our syntax analysis, parsing phase.
Pat yourself on the back if you made it till here. If you’ve followed everything until here, then you are equipped with the knowledge of writing a JSON parser by yourself. Write yourself a utility to print a formatted JSON Object and voila, you successfully wrote your very own JSON formatter. (Or you can use the print utility I wrote).
This isn’t the end though.
Now we delve into the world of manipulation of the JSON Object we just created, including retrieval, insertion, updates and deleting keys (and associated values) of the JSON Object. I’m almost certain no one uses JSON Objects only to format them. Lets begin!
Object Manipulation
The top level struct ObjectJson which we return after completion of parsing, stores a pointer to members. This represents a linked list, and thus, when a search is performed, we will have to manually traverse this list and compare the key of each member with the search key to find a match. This is O(N).
While O(N) Linear time is good, an improvement can be made. The JSON Specifications mentions that every key must be a string. We can take advantage of this fact, and build an efficient mechanism to search strings in O(Log(N)) time using String hashing.
Algorithm:
- Every string can be hashed, and an integral hash value can be calculated using a hash function. You can use FNV-1a (most commonly used) or just write one yourself like I did. Take 31 as the prime and build a string hash, do not use any module, let the hash overflow in a 64 bit space, this ensures we can store 18 quadrillion values in our JSON Object given there is sufficient memory).
- Now that we have an integral hash value, we need to store it somewhere that enables fast lookups, like a Set or a Binary Search Tree (BST). I chose to implement a BST since it can grow dynamically without copying values, which is what we might need to do when we create a set with a fixed size and an occupancy threshold. We will ignore rebalancing the tree for the time being.
- Create a BST Node and insert it to the existing BST. Ensure each BST Node contains reference to the value it stores, and the main ObjectJson struct as well. Point the
struct bst *htable;member to this existing BST, so that search can be performed on this htable. - When search is invoked, hash the key being searched and perform a lookup on the BST pointed to, by
*htable;of the ObjectJson on which search is invoked. - Return the Value to which the BST Node points to, if the key exists.
Our struct bst will look like:
struct bst {
long long hash;
Value *value;
bst *left;
bst *right;
};
Alright, I told you we will cirlce back to the create_bst(json) method. Here it is now:
void create_bst(ObjectJson *json) {
if (json->htable != NULL)
return;
bst *ROOT = __create_node();
Member *cur = json->members;
if (cur == NULL) {
json->htable = NULL;
return;
}
while (cur != NULL) {
// key contains double quote chars as well
// this is not desirable as double quote needs to be excluded when calculating hash
Token temp = cur->key;
temp.length -= 2;
if (temp.length > 0) {
temp.value++;
}
unsigned long long hash = create_hash(temp.value, temp.length);
insert_bst(ROOT, hash, cur->value);
if (cur->value->type == VAL_OBJ) {
Object *obj = (Object *)cur->value->as.obj;
if (obj->type == OBJ_JSON)
create_bst((ObjectJson *)obj);
}
cur = cur->next;
}
// todo: rebalance before assigning
json->htable = ROOT;
}
This method is invoked ON ObjectJson after parsing is completed. This is a one time activity and will initialize the htable pointer with the hashes of all keys in the ObjectJson. Note that, each nested ObjectJson will also contain a BST htable, specific to that nested object only. This implies, any nested JSON objects also support hash based retrievals and updates.
Our create_hash() methods is as follows
unsigned long long create_hash(char *key, int length) {
unsigned long long p = 31;
unsigned long long hash = 0;
for (int i = 0; i < length; i++) {
// if long then let overflow, it is equivalent to using a 2^64 module
hash += p * (key[i] - 'a' + 1);
p *= p;
}
// printf("hash %lld\n", hash);
return hash;
}
Simple, isn’t it?!
The procedure for fetching and insertion are pretty straightforward, now that you’re equipped with the knowledge of how we perform object manipulation.
It has been a really long article and so I’m going to end it here. Feel free to browse the source code. If you’re interesting in seeing the blason code in action: clone the repository, cd into it and execute the make command. Change a few lines in main.c and see how things react. Play with it at your own will.
Thank you for reading till the end :)
~rahultumpala